
Visitors
381The bizzare world of parsing dates in Spark
Dates are famously hard to work with, but it turns out dates are even harder in Spark
The numbers are off... but just slightly.
When I first stumbled across this it wasn't one of the bugs that just scream in your face - it was subtle. Something didn't add up, and after a lot of digging it became clear that things didn't add up around the year mark - repeatedly, but weirdly enough sometimes affecting a few days in December, and in other cases affecting a few days in January. But never both or neither.
Nothing unusal in the code, no warnings in the output - so what's going on?
Date parsing in Spark
Let's first look at an example. We're just gonna parse some dates from strings in Spark, that can't be too hard.
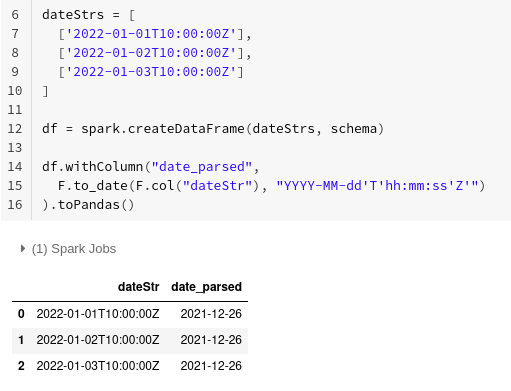
Turns out it is! That is quite a result though, it's not
If we change the year placeholder fromYYYY toyyyy things look like we want
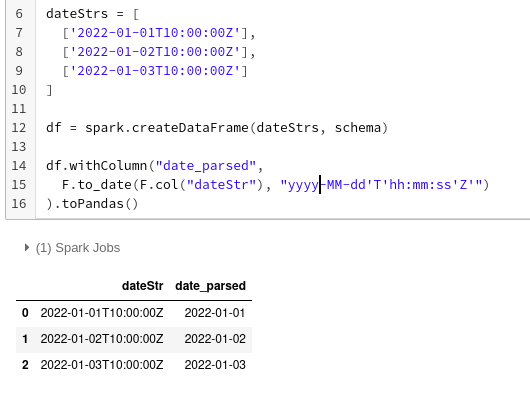
Y isn't y... most of the times
Clearly Y is at fault here, but what on earth does it do?
Checking theSpark docs doesn't turn out to be terribly helpful either, according to thoseY doesn't even exist.
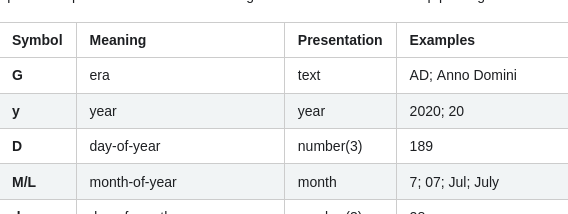
After some more digging it became clear that Spark uses Java's`SimpleDateFormat`, and guess what - that one does have aY.

And its calledWeek Year. Checking the docs linked above isn't actually terribly helpful, but0dates" >Wikipedia has a helpful description that started to make sense after reading it 5 times.
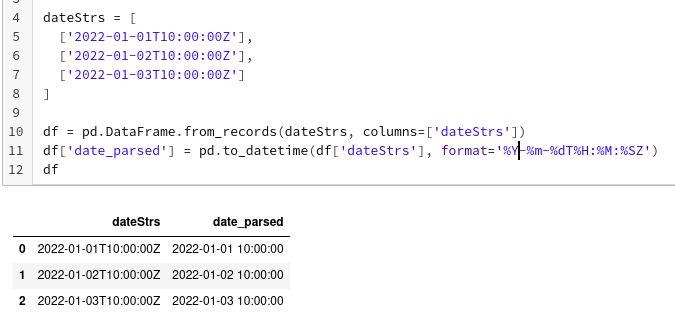
Now, funnily enough, Python uses theY in it's date format to a regular year, while ay means a year without the leading two century digits.
Spark 3
Luckily! This is no longer the case with Spark 3. Spark 3 now implements it's own date parser, and the behaviour described above is only possible if explicitely enabled.